







Similitud entre imágenes, análisis forense de imagen y control de calidad
Martes, 25 de Febrero de 2020 10:57

 Una de las casuísticas más comunes en el análisis forense de imagen, es la atribución de imágenes a un determinado autor. Imágenes, con frecuencia, publicadas sin autorización o distribuidas bajo autores no legítimos, las cuales son a menudo, manipuladas en sus dimensiones, perspectiva, contraste, colorido, etc.
Una de las casuísticas más comunes en el análisis forense de imagen, es la atribución de imágenes a un determinado autor. Imágenes, con frecuencia, publicadas sin autorización o distribuidas bajo autores no legítimos, las cuales son a menudo, manipuladas en sus dimensiones, perspectiva, contraste, colorido, etc.
Cuando una imagen contiene elementos característicos, ya sean sujetos que puedan dar testimonio de esa captura, o elementos que presenten una cierta aleatoridad como las nubes, el follaje, cursos de agua, etc. constituyen una firma inequívoca que dan testimonio del momento de la captura.
Sin embargo, cuando nos enfrentamos a escenas con un nivel de abstracción alto, como grandes aproximaciones, reproducciones de obras de arte, monumentos o paisajes muy característicos, la identificación como escenas únicas puede ser compleja.
A continuación veremos algunas estrategias basadas en visión por computadora que nos pueden ayudar a identificar y clasificar pares de imágenes sospechosas de similitud entre ellas.
¿Qué hace a una imagen única?
La altura, inclinación, angulación y tipo de lentes (longitud focal) empleados en la captura de la escena, implican un punto de vista único sobre la escena. Aun colocando dos cámaras a una misma distancia y altura de una misma escena, diferentes lentes implicaran diferentes aberraciones geométricas.
La métrica de la similitud
Desde hace décadas, el control de calidad de la imagen ha sido una inquietud en la transmisión y reproducción de imágenes, con el fin de aislar diferentes defectos que pueden aparecer durante su transmisión, como artefactos, ruido, aberraciones geométricas, etc.
Las primeras métricas utilizadas fueron las basadas en recuentos estadísticos a nivel de pixel, como la MSE (Mean Square Error) o la RMSE (Root Mean Square Error), sin embargo estas métricas aunque, difíciles de interpretar a nivel de escala (0- ∞) no informan adecuadamente sobre el error a nivel perceptivo, es decir, una imagen puede presentar un error por desviarse de su copia, pero este error no ser percibido como particularmente grave bajo nuestro sistema de percepción, eso no lleva a las métricas de naturaleza perceptiva o estructurales.

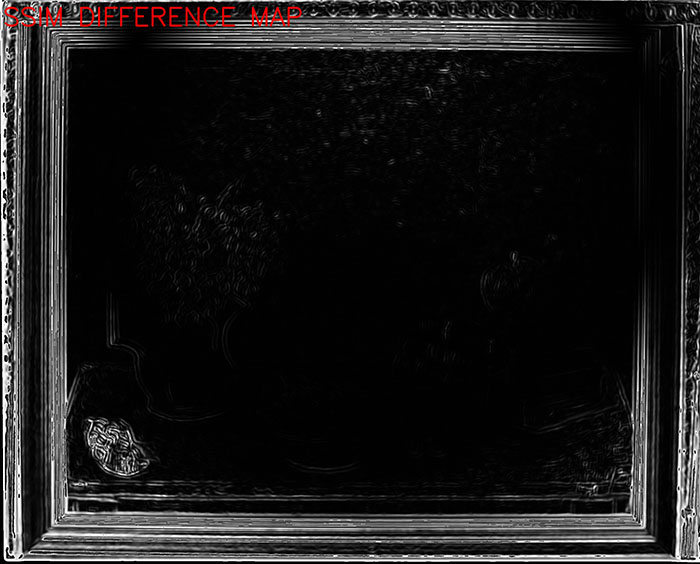
Imagen 1.- Evidencia en el mapa de similitud SSIM (zonas grises) de diferencias en los bordes de la imagen motivados por unas aberraciones geométricas diferentes entre los pares de imágenes estudiados. En negro las zonas idénticas.
Las métricas estructurales están fundamentadas en como el sistema de percepción reconoce una escena, a través de la luminosidad, contraste y estructura, es decir, detalles o variaciones del contraste a lo largo de la escena. Mientras las métricas tipo RMSE computan el pixel como unidad, las métricas estructurales parten de la dependencia de unos píxeles con otros. Así, la primera métrica de este tipo fue la “Universal Image Quality Index” (UQI) propuesta en 2002, y que pronto dio paso a una de las métricas más populares hoy en día conocida como SSIM (Structural Similarity) presenada en 2004 tras su primera versión MS-SSIM (Multi-Scale Structural Similarity ). La métrica SSIM es una de las estrategias más usadas para estimar la proximidad o similitud entre imágenes, o lo que es lo mismo el error entre las mismas. Una de las grandes ventajas de estas métricas, además de presentar rangos de unidades de 0-1, son los mapas de error producidos por la métrica SSIM, que nos permiten evaluar visualmente por donde se extienden las diferencias entre un par de imágenes, esto nos permite aislar de forma muy rápida donde se localiza el error o diferencia.

Imagen 2.- Evidencia de zonas clonadas o movidas entre los pares de imágenes, en gris-blanco se denotan las áreas con fuertes discrepancias.
El registro
Para poder comparar dos imágenes entre sí, es necesario que estas se superpongan de forma precisa, con la misma escala, relación de aspecto, etc. El registro automatizado de imágenes pasa por la detección de características comunes entre imágenes para determinar las transformaciones oportunas para ejecutar el registro de imágenes.
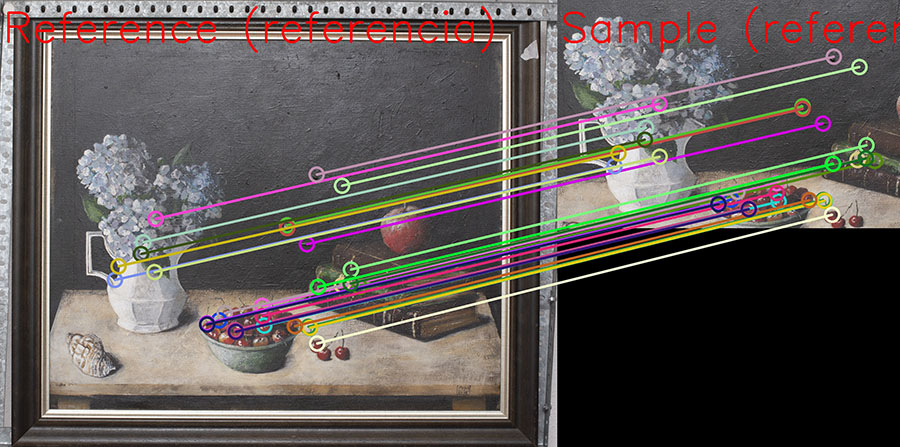
imagen 3.- Detección y coincidencia de caracteristicas (features) invariantes usando un algoritmo tipo SIFT
En 1999 las aportaciones de David Lowe con su conocido trabajo SIFT (Scale Invariant Feature Transform) fueron definitivas para desarrollar las estrategias de registro automatizadas como el moderno ORB (Oriented fast and Rotated BRIEF). Los mecanismos de detección de características o “features” sobre imágenes se basan la descripción de la imagen en diferentes vectores en orientación y magnitud invariantes respecto a la escala de la imagen. Esta capacidad para describir una imagen en base a sus características nos permite definir una matriz de transformación homográfica entre dichas imágenes que automatice el registro de una imagen respecto a la otra.

Imagen 4.- Registro de un fragmento de una imagen (imagen derivada) sobre su original tras la corrección de perspetiva y traslación (homografía)
El registro ente imágenes basado en el concepto SIFT nos permite automatizar grandes cantidades de imágenes, y deducir de forma rápida, como estas se relacionan entre sí a nivel espacial, por eso son los típicos algoritmos usados en fotogrametría en “stitching” de panoramas.
De esta forma, cuando comparamos una imagen, supuestamente derivada (recortada, manipulada en color, transformada en escala y perspectiva, etc) contra la imagen de la que supuestamente ha salido, podemos deducir de forma rápida, a que fragmento y posición ocupaba dentro de dicha imagen.
Conclusiones
La combinación de algoritmos de extracción de características, junto a transformaciones homográficas, de forma previa al empleo de métricas de similitud SSIM, son una importante herramienta en el análisis de imagen forense, con el fin de automatizar la detección de áreas de la imagen que han variado, como puede ser zonas manipuladas por clonado, e incluso discernir entre imágenes diferentes por la diferencia de punto de vista o aberraciones de lente.

Imagen 5.- Resultado del registro entre imágenes y cálculo de sus diferencias. en área en negro entre el perímetro blanco del mapa SSIM denota que el fragmento y su referencia son idénticos.
La gran ventaja de este proceso radica en que es muy fácil de implementar y automatizar con Python, usando las conocidas librerías OpenCV para trabajar con SIFT u ORB como detectores de características, y con Scikit-image o las librerías especializadas en métricas de error entre imagen Sewar. Por lo que es muy sencillo ejecutar estas tareas de comparación o estimación del error entre imágenes a lo largo de grandes colecciones de muestras y referencias y extraer indicadores objetivos de cuanto se diferencian entre sí dos imágenes.

Imagen 6.- Por la contra, cambios en la iluminación pueden ser puestos en evidencia, y cuantificados objetivamente, de una imagen a otra, dejando en evidencia que se trata de imágenes claramente diferentes, tomadas en circunstancias dispares.
Finalmente, cabe recordar, que la métrica SSIM ha sido desarrollada, en gran medida, en el seno del control de calidad en la imagen digital, su uso potencial para estimar diferencias entre imágenes que han sufrido fuertes procesos de compresión es fundamental en el seno de industrias como la del streaming. Aquí por ejemplo tenemos dos lecturas de la propia Netflix “Toward A Practical Perceptual Video Quality Metric” y “Scaling Image Validation Across Multiple Platforms” que nos introduce en el problema y estrategias del control de calidad en el video por estreaming, ya que es un formato donde los grandes ratios de compresión son fundamentales para el acceso a la información, de forma que esas métricas son fundamentales para estimar el deterioro de la imagen en función de los ratios de compresión y defectos en la transferencia.
| Próximo > |
|---|


